Kubernetes - kube-prometheus 배포해보기
Kubernetes를 monitoring하는 kube-prometheus를 배포해보았다.
Kubernetes v1.24.7 / kube-prometheus v0.12.0 / Ubuntu 22.04 LTS
Kubernetes
CLI
개요
kube-promethues는prometheus를kubernetes에서 쉽게 구축 할 수 있게 만들어 놓은 Solution이다.kube-prometheus에서의 HA 구성은 prometheus operator을 통해 HA(High availability)를 구성한다.prometheus는 pull-based 형식으로 interval을 두고 서버에서 각 수집 대상의 클라이언트를 찾아 metric을 scrape하는 방식이다.
반대인 push-based는 클라이언트에서 미리 gathering 한 뒤 서버로 보냄(ex.graphite,beats등)
kubernetes에서는pod의 배포 방식에 따라 scale을 하기 때문에 지워졌다 만들어졌다 하는 경우가 반복 되기 때문에 pull-based가 어울린다고 볼 수 있다.
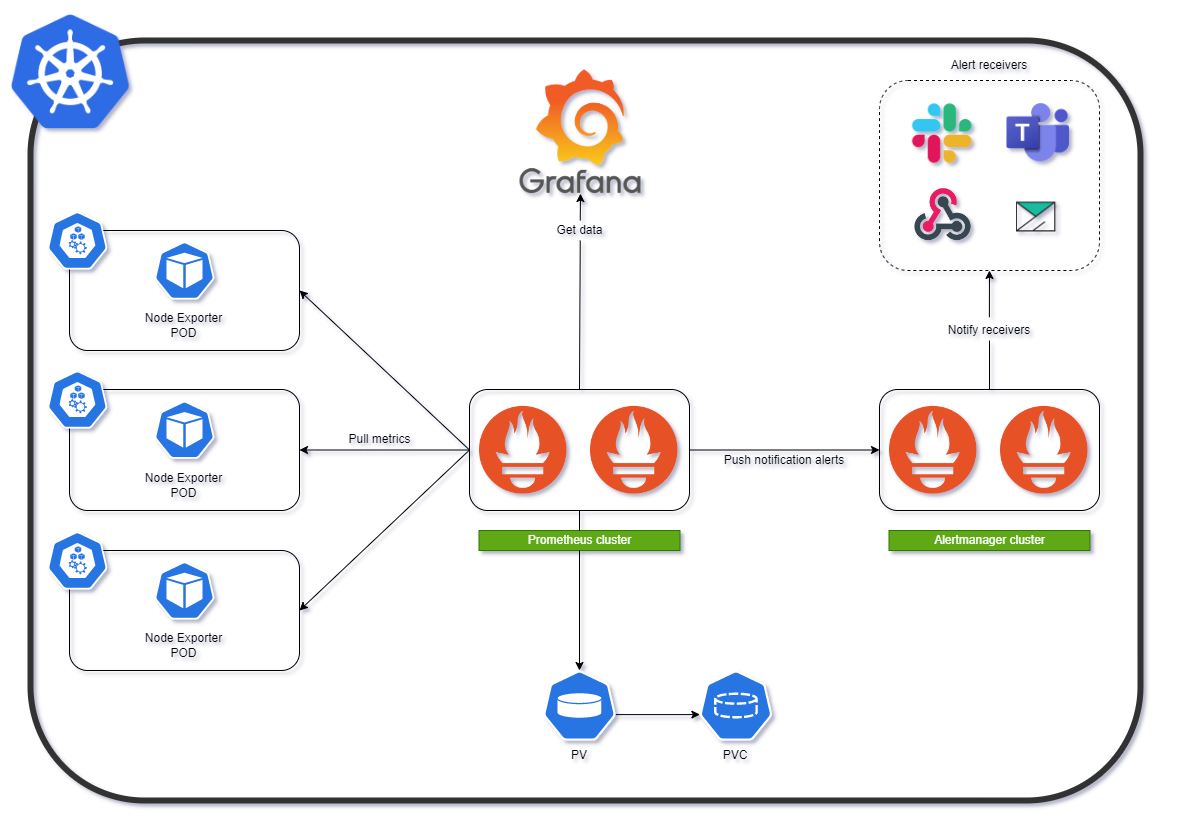 kube-prometheus 구성도
kube-prometheus 구성도
ref.
TL;DR
설치는 다음의 링크를 참조하면 된다.
https://github.com/prometheus-operator/kube-prometheus#quickstart
기본적으로 kube-prometheus에는 다음과 같이 구성이 들어간다.
- prometheus server (2 replicas)
- prometheus operator
- alertmanager (3 replicas)
- node-exporter
- grafana
다른 설정이 필요 없다면 Quickstart항목대로만 따라 하면 된다.
1
2
3
4
5
6
7
8
9
# Quickstart
git clone https://github.com/prometheus-operator/kube-prometheus.git
cd kube-prometheus
kubectl apply --server-side -f ./manifests/setup
kubectl wait \
--for condition=Established \
--all CustomResourceDefinition \
--namespace=monitoring
kubectl apply -f ./manifests
잘 만들어졌다면 실제 구성된 cluster에서 pod를 확인 해본다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# pod 확인(구성 이후의 상태이므로 실제로 구축과는 다를 수 있음)
dor1@is-master:~$ kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 2d22h
alertmanager-main-1 2/2 Running 0 2d22h
alertmanager-main-2 2/2 Running 0 2d22h
blackbox-exporter-58c9c5ff8d-pb4jn 3/3 Running 0 2d22h
grafana-59d96cb767-ghk6w 1/1 Running 3 (2d5h ago) 2d5h
kube-state-metrics-6d454b6f84-jrhr8 3/3 Running 0 2d22h
node-exporter-2sx9v 2/2 Running 0 2d22h
node-exporter-6rz8v 2/2 Running 0 2d22h
node-exporter-bwc9v 2/2 Running 0 2d22h
node-exporter-j85sx 2/2 Running 0 2d22h
prometheus-adapter-678b454b8b-k2psx 1/1 Running 1 (2d22h ago) 2d22h
prometheus-adapter-678b454b8b-qfmb4 1/1 Running 1 (2d22h ago) 2d22h
prometheus-k8s-0 2/2 Running 0 2d22h
prometheus-k8s-1 2/2 Running 0 2d22h
prometheus-operator-7bb9877c54-drjlf 2/2 Running 0 2d22h
rook-ceph을 PVC로 사용하여 deploy
Testbed
1
2
3
4
5
6
dor1@is-master:~$ kubectl get node
NAME STATUS ROLES AGE VERSION
is-master Ready control-plane 8d v1.24.7
is-worker1 Ready worker 8d v1.24.7
is-worker2 Ready worker 8d v1.24.7
is-worker3 Ready worker 8d v1.24.7
기본적으로 rook-ceph이 구성되어 있는 환경에서 진행한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
dor1@is-master:~$ kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-64p98 2/2 Running 4 (7d17h ago) 9d
csi-cephfsplugin-d9gb2 2/2 Running 4 (7d17h ago) 9d
csi-cephfsplugin-fg5f2 2/2 Running 4 (7d17h ago) 9d
csi-cephfsplugin-provisioner-7c594f8cf-clfrz 5/5 Running 10 (7d17h ago) 9d
csi-cephfsplugin-provisioner-7c594f8cf-gx2q7 5/5 Running 10 (7d17h ago) 9d
csi-rbdplugin-74vqr 2/2 Running 4 (7d17h ago) 9d
csi-rbdplugin-provisioner-99dd6c4c6-gpzs4 5/5 Running 10 (7d17h ago) 9d
csi-rbdplugin-provisioner-99dd6c4c6-x2bs7 5/5 Running 10 (7d17h ago) 9d
csi-rbdplugin-tmfmr 2/2 Running 4 (7d17h ago) 9d
csi-rbdplugin-vnppv 2/2 Running 4 (7d17h ago) 9d
rook-ceph-crashcollector-is-worker1-845b749546-wv5wv 1/1 Running 2 (7d17h ago) 7d19h
rook-ceph-crashcollector-is-worker2-59df576ffc-h9rb9 1/1 Running 0 3d17h
rook-ceph-crashcollector-is-worker3-64df8c6cd6-7cc6n 1/1 Running 0 3d17h
rook-ceph-mds-cephfs-a-6df48cbdb8-ngrsg 2/2 Running 4 (7d17h ago) 7d19h
rook-ceph-mds-cephfs-b-c67d6677c-jgx2g 2/2 Running 0 3d17h
rook-ceph-mgr-a-644b9d9f4f-fg4c7 3/3 Running 0 3d17h
rook-ceph-mgr-b-6cdf547fbd-qjnlh 3/3 Running 7 (7d17h ago) 8d
rook-ceph-mon-a-5c64dbb64f-258rt 2/2 Running 4 (7d17h ago) 9d
rook-ceph-mon-b-7fc6cd8568-tssnd 2/2 Running 4 (7d17h ago) 9d
rook-ceph-mon-c-66cc996cd6-svwxn 2/2 Running 4 (7d17h ago) 9d
rook-ceph-operator-cb99d8d4d-5hclf 1/1 Running 4 (7d17h ago) 9d
rook-ceph-osd-0-6485bcf87f-99nv6 2/2 Running 4 (7d17h ago) 9d
rook-ceph-osd-1-9656b7658-5gvss 2/2 Running 4 (7d17h ago) 9d
rook-ceph-osd-2-589764bf94-vnhds 2/2 Running 4 (7d17h ago) 9d
rook-ceph-osd-3-88b88977c-9kp7m 2/2 Running 4 (7d17h ago) 9d
rook-ceph-osd-4-86bcc48d5b-ttmzf 2/2 Running 4 (7d17h ago) 9d
rook-ceph-osd-5-755c7c5866-fnvrp 2/2 Running 4 (7d17h ago) 9d
rook-ceph-osd-prepare-is-worker1-nvsch 0/1 Completed 0 75m
rook-ceph-osd-prepare-is-worker2-w26qq 0/1 Completed 0 75m
rook-ceph-osd-prepare-is-worker3-cbvmb 0/1 Completed 0 75m
rook-ceph-tools-7857bc9568-262sx 1/1 Running 2 (7d17h ago) 7d23h
dor1@is-master:~$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-cephfs rook-ceph.cephfs.csi.ceph.com Retain Immediate true 3d20h
1. prometheus와 alertmanager의 구성 수정
prometheus-operator는 Kubenetes crd를 사용하여 management, deployment가 된다.
rook-ceph을 사용하기 전에는 manifests안의 내용을 수정해야 하므로, 우선 CRD까지 배포를 진행한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
dor1@is-master:~$ git clone https://github.com/prometheus-operator/kube-prometheus.git
Cloning into 'kube-prometheus'...
remote: Enumerating objects: 17562, done.
remote: Counting objects: 100% (112/112), done.
remote: Compressing objects: 100% (72/72), done.
remote: Total 17562 (delta 63), reused 73 (delta 35), pack-reused 17450
Receiving objects: 100% (17562/17562), 9.25 MiB | 4.53 MiB/s, done.
Resolving deltas: 100% (11569/11569), done.
# 작업은 대체적으로 manifests 안에서 이뤄짐
dor1@is-master:~$ cd kube-prometheus/manifests
dor1@is-master:~/kube-prometheus/manifests$ kubectl apply --server-side -f ./setup
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com serverside-applied
dor1@is-master:~/kube-prometheus/manifests$ kubectl wait --for condition=Established --all CustomResourceDefinition --namespace=monitoring
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/bgpconfigurations.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/bgppeers.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/blockaffinities.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/caliconodestatuses.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/cephblockpoolradosnamespaces.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephblockpools.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephbucketnotifications.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephbuckettopics.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephclients.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephclusters.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephfilesystemmirrors.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephfilesystems.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephfilesystemsubvolumegroups.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephnfses.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephobjectrealms.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephobjectstores.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephobjectstoreusers.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephobjectzonegroups.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephobjectzones.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/cephrbdmirrors.ceph.rook.io condition met
customresourcedefinition.apiextensions.k8s.io/clusterinformations.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/felixconfigurations.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/globalnetworkpolicies.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/globalnetworksets.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/hostendpoints.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/ipamblocks.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/ipamconfigs.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/ipamhandles.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/ippools.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/ipreservations.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/kubecontrollersconfigurations.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/networkpolicies.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/networksets.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/objectbucketclaims.objectbucket.io condition met
customresourcedefinition.apiextensions.k8s.io/objectbuckets.objectbucket.io condition met
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com condition met
# crd 확인
dor1@is-master:~/kube-prometheus/manifests$ kubectl get crd
NAME CREATED AT
alertmanagerconfigs.monitoring.coreos.com 2023-02-10T02:38:29Z
alertmanagers.monitoring.coreos.com 2023-02-10T02:38:29Z
bgpconfigurations.crd.projectcalico.org 2023-01-31T08:10:06Z
bgppeers.crd.projectcalico.org 2023-01-31T08:10:06Z
blockaffinities.crd.projectcalico.org 2023-01-31T08:10:06Z
caliconodestatuses.crd.projectcalico.org 2023-01-31T08:10:06Z
cephblockpoolradosnamespaces.ceph.rook.io 2023-01-31T09:28:49Z
cephblockpools.ceph.rook.io 2023-01-31T09:28:49Z
cephbucketnotifications.ceph.rook.io 2023-01-31T09:28:49Z
cephbuckettopics.ceph.rook.io 2023-01-31T09:28:49Z
cephclients.ceph.rook.io 2023-01-31T09:28:49Z
cephclusters.ceph.rook.io 2023-01-31T09:28:49Z
cephfilesystemmirrors.ceph.rook.io 2023-01-31T09:28:50Z
cephfilesystems.ceph.rook.io 2023-01-31T09:28:50Z
cephfilesystemsubvolumegroups.ceph.rook.io 2023-01-31T09:28:50Z
cephnfses.ceph.rook.io 2023-01-31T09:28:50Z
cephobjectrealms.ceph.rook.io 2023-01-31T09:28:51Z
cephobjectstores.ceph.rook.io 2023-01-31T09:28:51Z
cephobjectstoreusers.ceph.rook.io 2023-01-31T09:28:51Z
cephobjectzonegroups.ceph.rook.io 2023-01-31T09:28:51Z
cephobjectzones.ceph.rook.io 2023-01-31T09:28:51Z
cephrbdmirrors.ceph.rook.io 2023-01-31T09:28:51Z
clusterinformations.crd.projectcalico.org 2023-01-31T08:10:06Z
felixconfigurations.crd.projectcalico.org 2023-01-31T08:10:06Z
globalnetworkpolicies.crd.projectcalico.org 2023-01-31T08:10:06Z
globalnetworksets.crd.projectcalico.org 2023-01-31T08:10:06Z
hostendpoints.crd.projectcalico.org 2023-01-31T08:10:07Z
ipamblocks.crd.projectcalico.org 2023-01-31T08:10:07Z
ipamconfigs.crd.projectcalico.org 2023-01-31T08:10:07Z
ipamhandles.crd.projectcalico.org 2023-01-31T08:10:07Z
ippools.crd.projectcalico.org 2023-01-31T08:10:07Z
ipreservations.crd.projectcalico.org 2023-01-31T08:10:07Z
kubecontrollersconfigurations.crd.projectcalico.org 2023-01-31T08:10:07Z
networkpolicies.crd.projectcalico.org 2023-01-31T08:10:07Z
networksets.crd.projectcalico.org 2023-01-31T08:10:07Z
objectbucketclaims.objectbucket.io 2023-01-31T09:28:51Z
objectbuckets.objectbucket.io 2023-01-31T09:28:51Z
podmonitors.monitoring.coreos.com 2023-02-10T02:38:30Z
probes.monitoring.coreos.com 2023-02-10T02:38:30Z
prometheuses.monitoring.coreos.com 2023-02-10T02:38:30Z
prometheusrules.monitoring.coreos.com 2023-02-10T02:38:30Z
servicemonitors.monitoring.coreos.com 2023-02-10T02:38:30Z
thanosrulers.monitoring.coreos.com 2023-02-10T02:38:31Z
rook-ceph의 PV를 사용하기 위해서는 deployment 하기 전 prometheus와 alertmanager의 statefulSet을 구성을 변경해줘야 한다.
또한, prometheus-operator는 아키텍처 상 prometheus의 replicas가 기본 2개, alertmanager의 replicas는 기본 3개로 구성되어있어 PV를 구성할 때, pod 당 할당되는 용량으로 계산 해야 한다.
metrics의 대해 너무 용량에 압박이 심할 것 같으면 prometheus에 retention policy를 넣어 PVC의 retention 관리도 같이 해줄 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
# prometheus 구성 변경(PVC 추가)
dor1@is-master:~/kube-prometheus/manifests$ vi prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.41.0
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
enableFeatures: []
externalLabels: {}
image: quay.io/prometheus/prometheus:v2.41.0
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.41.0
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleNamespaceSelector: {}
ruleSelector: {}
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.41.0
# add PVC and retention policy
retention: 30d
storage:
volumeClaimTemplate:
spec:
# rook-cpeh의 storageClass
storageClassName: rook-cephfs
resources:
requests:
# pod 당 500Gib, 즉 2 replica에서는 1Tib를 차지 함
storage: 500Gi
# alertmanager 구성 변경(PVC 추가)
dor1@is-master:~/kube-prometheus/manifests$ vi alertmanager-alertmanager.yaml
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.25.0
name: main
namespace: monitoring
spec:
image: quay.io/prometheus/alertmanager:v0.25.0
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.25.0
replicas: 3
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 4m
memory: 100Mi
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: alertmanager-main
version: 0.25.0
# add PVC
storage:
volumeClaimTemplate:
spec:
# rook-cpeh의 storageClass
storageClassName: rook-cephfs
resources:
requests:
# pod 당 50Gib, 즉 3 replica에서는 150Gib를 차지 함
storage: 50Gi
2. grafana에 PVC 추가
grafana같은 경우엔 CRD로 관리가 안되므로 PVC를 새롭게 작성해주고 grafana-deployment.yaml에서 PVC를 바라볼 수 있도록 수정 해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
# grafana-pvc.yaml 수정
dor1@is-master:~/kube-prometheus/manifests$ vi grafana-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-cephfs-pvc
namespace: monitoring
spec:
# rook-ceph의 storageClass
storageClassName: rook-cephfs
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi
# grafana-deployment.yaml 수정
dor1@is-master:~/kube-prometheus/manifests$ vi grafana-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 9.3.2
name: grafana
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
template:
metadata:
annotations:
checksum/grafana-config: adbde4cde1aa3ca57c408943af53e6f7
checksum/grafana-dashboardproviders: d8fb24844314114bed088b83042b1bdb
checksum/grafana-datasources: 0800bab7ea1e2d8ad5c09586d089e033
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 9.3.2
spec:
automountServiceAccountToken: false
containers:
- env: []
image: grafana/grafana:9.3.2
name: grafana
ports:
- containerPort: 3000
name: http
readinessProbe:
httpGet:
path: /api/health
port: http
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-storage
readOnly: false
- mountPath: /etc/grafana/provisioning/datasources
name: grafana-datasources
readOnly: false
- mountPath: /etc/grafana/provisioning/dashboards
name: grafana-dashboards
readOnly: false
- mountPath: /tmp
name: tmp-plugins
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/alertmanager-overview
name: grafana-dashboard-alertmanager-overview
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/apiserver
name: grafana-dashboard-apiserver
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/cluster-total
name: grafana-dashboard-cluster-total
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/controller-manager
name: grafana-dashboard-controller-manager
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/grafana-overview
name: grafana-dashboard-grafana-overview
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/k8s-resources-cluster
name: grafana-dashboard-k8s-resources-cluster
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/k8s-resources-namespace
name: grafana-dashboard-k8s-resources-namespace
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/k8s-resources-node
name: grafana-dashboard-k8s-resources-node
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/k8s-resources-pod
name: grafana-dashboard-k8s-resources-pod
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/k8s-resources-workload
name: grafana-dashboard-k8s-resources-workload
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/k8s-resources-workloads-namespace
name: grafana-dashboard-k8s-resources-workloads-namespace
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/kubelet
name: grafana-dashboard-kubelet
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/namespace-by-pod
name: grafana-dashboard-namespace-by-pod
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/namespace-by-workload
name: grafana-dashboard-namespace-by-workload
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/node-cluster-rsrc-use
name: grafana-dashboard-node-cluster-rsrc-use
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/node-rsrc-use
name: grafana-dashboard-node-rsrc-use
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/nodes-darwin
name: grafana-dashboard-nodes-darwin
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/nodes
name: grafana-dashboard-nodes
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/persistentvolumesusage
name: grafana-dashboard-persistentvolumesusage
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/pod-total
name: grafana-dashboard-pod-total
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/prometheus-remote-write
name: grafana-dashboard-prometheus-remote-write
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/prometheus
name: grafana-dashboard-prometheus
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/proxy
name: grafana-dashboard-proxy
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/scheduler
name: grafana-dashboard-scheduler
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/workload-total
name: grafana-dashboard-workload-total
readOnly: false
- mountPath: /etc/grafana
name: grafana-config
readOnly: false
nodeSelector:
kubernetes.io/os: linux
securityContext:
fsGroup: 65534
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: grafana
volumes:
# pod 내 설정 저장은 사용 안할거라 주석처리
#- emptyDir: {}
#name: grafana-storage
# pvc 추가
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-cephfs-pvc
#---------------------------------------
- name: grafana-datasources
secret:
secretName: grafana-datasources
- configMap:
name: grafana-dashboards
name: grafana-dashboards
- emptyDir:
medium: Memory
name: tmp-plugins
- configMap:
name: grafana-dashboard-alertmanager-overview
name: grafana-dashboard-alertmanager-overview
- configMap:
name: grafana-dashboard-apiserver
name: grafana-dashboard-apiserver
- configMap:
name: grafana-dashboard-cluster-total
name: grafana-dashboard-cluster-total
- configMap:
name: grafana-dashboard-controller-manager
name: grafana-dashboard-controller-manager
- configMap:
name: grafana-dashboard-grafana-overview
name: grafana-dashboard-grafana-overview
- configMap:
name: grafana-dashboard-k8s-resources-cluster
name: grafana-dashboard-k8s-resources-cluster
- configMap:
name: grafana-dashboard-k8s-resources-namespace
name: grafana-dashboard-k8s-resources-namespace
- configMap:
name: grafana-dashboard-k8s-resources-node
name: grafana-dashboard-k8s-resources-node
- configMap:
name: grafana-dashboard-k8s-resources-pod
name: grafana-dashboard-k8s-resources-pod
- configMap:
name: grafana-dashboard-k8s-resources-workload
name: grafana-dashboard-k8s-resources-workload
- configMap:
name: grafana-dashboard-k8s-resources-workloads-namespace
name: grafana-dashboard-k8s-resources-workloads-namespace
- configMap:
name: grafana-dashboard-kubelet
name: grafana-dashboard-kubelet
- configMap:
name: grafana-dashboard-namespace-by-pod
name: grafana-dashboard-namespace-by-pod
- configMap:
name: grafana-dashboard-namespace-by-workload
name: grafana-dashboard-namespace-by-workload
- configMap:
name: grafana-dashboard-node-cluster-rsrc-use
name: grafana-dashboard-node-cluster-rsrc-use
- configMap:
name: grafana-dashboard-node-rsrc-use
name: grafana-dashboard-node-rsrc-use
- configMap:
name: grafana-dashboard-nodes-darwin
name: grafana-dashboard-nodes-darwin
- configMap:
name: grafana-dashboard-nodes
name: grafana-dashboard-nodes
- configMap:
name: grafana-dashboard-persistentvolumesusage
name: grafana-dashboard-persistentvolumesusage
- configMap:
name: grafana-dashboard-pod-total
name: grafana-dashboard-pod-total
- configMap:
name: grafana-dashboard-prometheus-remote-write
name: grafana-dashboard-prometheus-remote-write
- configMap:
name: grafana-dashboard-prometheus
name: grafana-dashboard-prometheus
- configMap:
name: grafana-dashboard-proxy
name: grafana-dashboard-proxy
- configMap:
name: grafana-dashboard-scheduler
name: grafana-dashboard-scheduler
- configMap:
name: grafana-dashboard-workload-total
name: grafana-dashboard-workload-total
- name: grafana-config
secret:
secretName: grafana-config
3. Deployment
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
dor1@is-master:~/kube-prometheus/manifests$ kubectl apply -f .
alertmanager.monitoring.coreos.com/main created
poddisruptionbudget.policy/alertmanager-main created
prometheusrule.monitoring.coreos.com/alertmanager-main-rules created
secret/alertmanager-main created
service/alertmanager-main created
serviceaccount/alertmanager-main created
servicemonitor.monitoring.coreos.com/alertmanager-main created
clusterrole.rbac.authorization.k8s.io/blackbox-exporter created
clusterrolebinding.rbac.authorization.k8s.io/blackbox-exporter created
configmap/blackbox-exporter-configuration created
deployment.apps/blackbox-exporter created
service/blackbox-exporter created
serviceaccount/blackbox-exporter created
servicemonitor.monitoring.coreos.com/blackbox-exporter created
secret/grafana-config created
secret/grafana-datasources created
configmap/grafana-dashboard-alertmanager-overview created
configmap/grafana-dashboard-apiserver created
configmap/grafana-dashboard-cluster-total created
configmap/grafana-dashboard-controller-manager created
configmap/grafana-dashboard-grafana-overview created
configmap/grafana-dashboard-k8s-resources-cluster created
configmap/grafana-dashboard-k8s-resources-namespace created
configmap/grafana-dashboard-k8s-resources-node created
configmap/grafana-dashboard-k8s-resources-pod created
configmap/grafana-dashboard-k8s-resources-workload created
configmap/grafana-dashboard-k8s-resources-workloads-namespace created
configmap/grafana-dashboard-kubelet created
configmap/grafana-dashboard-namespace-by-pod created
configmap/grafana-dashboard-namespace-by-workload created
configmap/grafana-dashboard-node-cluster-rsrc-use created
configmap/grafana-dashboard-node-rsrc-use created
configmap/grafana-dashboard-nodes-darwin created
configmap/grafana-dashboard-nodes created
configmap/grafana-dashboard-persistentvolumesusage created
configmap/grafana-dashboard-pod-total created
configmap/grafana-dashboard-prometheus-remote-write created
configmap/grafana-dashboard-prometheus created
configmap/grafana-dashboard-proxy created
configmap/grafana-dashboard-scheduler created
configmap/grafana-dashboard-workload-total created
configmap/grafana-dashboards created
deployment.apps/grafana created
prometheusrule.monitoring.coreos.com/grafana-rules created
persistentvolumeclaim/grafana-cephfs-pvc created
service/grafana created
serviceaccount/grafana created
servicemonitor.monitoring.coreos.com/grafana created
prometheusrule.monitoring.coreos.com/kube-prometheus-rules created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kube-state-metrics-rules created
service/kube-state-metrics created
serviceaccount/kube-state-metrics created
servicemonitor.monitoring.coreos.com/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kubernetes-monitoring-rules created
servicemonitor.monitoring.coreos.com/kube-apiserver created
servicemonitor.monitoring.coreos.com/coredns created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
servicemonitor.monitoring.coreos.com/kube-scheduler created
servicemonitor.monitoring.coreos.com/kubelet created
clusterrole.rbac.authorization.k8s.io/node-exporter created
clusterrolebinding.rbac.authorization.k8s.io/node-exporter created
daemonset.apps/node-exporter created
prometheusrule.monitoring.coreos.com/node-exporter-rules created
service/node-exporter created
serviceaccount/node-exporter created
servicemonitor.monitoring.coreos.com/node-exporter created
clusterrole.rbac.authorization.k8s.io/prometheus-k8s created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created
poddisruptionbudget.policy/prometheus-k8s created
prometheus.monitoring.coreos.com/k8s created
prometheusrule.monitoring.coreos.com/prometheus-k8s-prometheus-rules created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s-config created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
service/prometheus-k8s created
serviceaccount/prometheus-k8s created
servicemonitor.monitoring.coreos.com/prometheus-k8s created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
clusterrole.rbac.authorization.k8s.io/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created
clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created
configmap/adapter-config created
deployment.apps/prometheus-adapter created
poddisruptionbudget.policy/prometheus-adapter created
rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created
service/prometheus-adapter created
serviceaccount/prometheus-adapter created
servicemonitor.monitoring.coreos.com/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
prometheusrule.monitoring.coreos.com/prometheus-operator-rules created
service/prometheus-operator created
serviceaccount/prometheus-operator created
servicemonitor.monitoring.coreos.com/prometheus-operator created
# 확인
dor1@is-master:~/kube-prometheus/manifests$ kubectl get pod,cm,svc,pv,pvc -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-main-0 2/2 Running 0 119s
pod/alertmanager-main-1 2/2 Running 0 119s
pod/alertmanager-main-2 2/2 Running 0 119s
pod/blackbox-exporter-58c9c5ff8d-92nlc 3/3 Running 0 2m15s
pod/grafana-59d96cb767-2jnr9 1/1 Running 0 2m13s
pod/kube-state-metrics-6d454b6f84-8bf8r 3/3 Running 0 2m13s
pod/node-exporter-6wd54 2/2 Running 0 2m12s
pod/node-exporter-j6kmd 2/2 Running 0 2m12s
pod/node-exporter-q67hx 2/2 Running 0 2m12s
pod/node-exporter-qs7nf 2/2 Running 0 2m12s
pod/prometheus-adapter-678b454b8b-h55gr 1/1 Running 1 (44s ago) 2m11s
pod/prometheus-adapter-678b454b8b-lj446 1/1 Running 0 2m11s
pod/prometheus-k8s-0 2/2 Running 0 112s
pod/prometheus-k8s-1 2/2 Running 0 112s
pod/prometheus-operator-7bb9877c54-vk8mt 2/2 Running 0 2m11s
NAME DATA AGE
configmap/adapter-config 1 2m11s
configmap/blackbox-exporter-configuration 1 2m15s
configmap/grafana-dashboard-alertmanager-overview 1 2m14s
configmap/grafana-dashboard-apiserver 1 2m14s
configmap/grafana-dashboard-cluster-total 1 2m14s
configmap/grafana-dashboard-controller-manager 1 2m14s
configmap/grafana-dashboard-grafana-overview 1 2m14s
configmap/grafana-dashboard-k8s-resources-cluster 1 2m14s
configmap/grafana-dashboard-k8s-resources-namespace 1 2m14s
configmap/grafana-dashboard-k8s-resources-node 1 2m14s
configmap/grafana-dashboard-k8s-resources-pod 1 2m14s
configmap/grafana-dashboard-k8s-resources-workload 1 2m14s
configmap/grafana-dashboard-k8s-resources-workloads-namespace 1 2m14s
configmap/grafana-dashboard-kubelet 1 2m13s
configmap/grafana-dashboard-namespace-by-pod 1 2m13s
configmap/grafana-dashboard-namespace-by-workload 1 2m13s
configmap/grafana-dashboard-node-cluster-rsrc-use 1 2m13s
configmap/grafana-dashboard-node-rsrc-use 1 2m13s
configmap/grafana-dashboard-nodes 1 2m13s
configmap/grafana-dashboard-nodes-darwin 1 2m13s
configmap/grafana-dashboard-persistentvolumesusage 1 2m13s
configmap/grafana-dashboard-pod-total 1 2m13s
configmap/grafana-dashboard-prometheus 1 2m13s
configmap/grafana-dashboard-prometheus-remote-write 1 2m13s
configmap/grafana-dashboard-proxy 1 2m13s
configmap/grafana-dashboard-scheduler 1 2m13s
configmap/grafana-dashboard-workload-total 1 2m13s
configmap/grafana-dashboards 1 2m13s
configmap/kube-root-ca.crt 1 3h21m
configmap/prometheus-k8s-rulefiles-0 8 114s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-main ClusterIP 10.233.7.67 <none> 9093/TCP,8080/TCP 2m15s
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 119s
service/blackbox-exporter ClusterIP 10.233.23.184 <none> 9115/TCP,19115/TCP 2m15s
service/grafana ClusterIP 10.233.21.230 <none> 3000/TCP 2m13s
service/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 2m13s
service/node-exporter ClusterIP None <none> 9100/TCP 2m12s
service/prometheus-adapter ClusterIP 10.233.37.112 <none> 443/TCP 2m11s
service/prometheus-k8s ClusterIP 10.233.5.10 <none> 9090/TCP,8080/TCP 2m12s
service/prometheus-operated ClusterIP None <none> 9090/TCP 112s
service/prometheus-operator ClusterIP None <none> 8443/TCP 2m11s
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-5c06219b-9d7d-43d7-9813-e659f6cbfb24 50Gi RWO Retain Bound monitoring/alertmanager-main-db-alertmanager-main-2 rook-cephfs 118s
persistentvolume/pvc-791db39e-8550-43c7-81e0-001a7d613a27 500Gi RWO Retain Bound monitoring/prometheus-k8s-db-prometheus-k8s-0 rook-cephfs 111s
persistentvolume/pvc-7f05b314-d987-4748-b954-2b21a891b5b0 50Gi RWO Retain Bound monitoring/alertmanager-main-db-alertmanager-main-1 rook-cephfs 118s
persistentvolume/pvc-c7f7f953-67d3-43aa-b83f-5b1422b8f7d5 50Gi RWO Retain Bound monitoring/grafana-cephfs-pvc rook-cephfs 2m12s
persistentvolume/pvc-d28e8a24-586d-4fca-87cd-cc66dee62d89 50Gi RWO Retain Bound monitoring/alertmanager-main-db-alertmanager-main-0 rook-cephfs 118s
persistentvolume/pvc-dcc4e8e3-73dc-42d7-b28c-6593cd8a65c7 500Gi RWO Retain Bound monitoring/prometheus-k8s-db-prometheus-k8s-1 rook-cephfs 111s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/alertmanager-main-db-alertmanager-main-0 Bound pvc-d28e8a24-586d-4fca-87cd-cc66dee62d89 50Gi RWO rook-cephfs 119s
persistentvolumeclaim/alertmanager-main-db-alertmanager-main-1 Bound pvc-7f05b314-d987-4748-b954-2b21a891b5b0 50Gi RWO rook-cephfs 119s
persistentvolumeclaim/alertmanager-main-db-alertmanager-main-2 Bound pvc-5c06219b-9d7d-43d7-9813-e659f6cbfb24 50Gi RWO rook-cephfs 119s
persistentvolumeclaim/grafana-cephfs-pvc Bound pvc-c7f7f953-67d3-43aa-b83f-5b1422b8f7d5 50Gi RWO rook-cephfs 2m13s
persistentvolumeclaim/prometheus-k8s-db-prometheus-k8s-0 Bound pvc-791db39e-8550-43c7-81e0-001a7d613a27 500Gi RWO rook-cephfs 112s
persistentvolumeclaim/prometheus-k8s-db-prometheus-k8s-1 Bound pvc-dcc4e8e3-73dc-42d7-b28c-6593cd8a65c7 500Gi RWO rook-cephfs 112s
4. 확인
grafana에 접근을 하려면 nodePort가 안되어있어 수정을 해줘야 한다.
worker node에서 사용할 수 있는 nodePort의 범위는 30000-32767이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
dor1@is-master:~/kube-prometheus/manifests$ kubectl edit svc -n monitoring grafana
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2023-02-10T05:57:51Z"
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 9.3.2
name: grafana
namespace: monitoring
resourceVersion: "1577513"
uid: f375b99b-f1df-4c64-b13a-1c0cd3ef7a30
spec:
clusterIP: 10.233.21.230
clusterIPs:
- 10.233.21.230
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: http
# nodePort 지정
nodePort: 30300
port: 3000
protocol: TCP
targetPort: http
selector:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
sessionAffinity: None
# ClusterIP -> NodePor 변경
type: NodePort
status:
loadBalancer: {}
service/grafana edited
# 확인
dor1@is-master:~/kube-prometheus/manifests$ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.233.7.67 <none> 9093/TCP,8080/TCP 8m47s
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 8m31s
blackbox-exporter ClusterIP 10.233.23.184 <none> 9115/TCP,19115/TCP 8m47s
grafana NodePort 10.233.21.230 <none> 3000:30300/TCP 8m45s
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 8m45s
node-exporter ClusterIP None <none> 9100/TCP 8m44s
prometheus-adapter ClusterIP 10.233.37.112 <none> 443/TCP 8m43s
prometheus-k8s ClusterIP 10.233.5.10 <none> 9090/TCP,8080/TCP 8m44s
prometheus-operated ClusterIP None <none> 9090/TCP 8m24s
prometheus-operator ClusterIP None <none> 8443/TCP 8m43s
정상적으로 nodePort로 변경이 되었다면 끝나면 접속을 해본다.
만약 nodePort가 제대로 변경이 됐음에도 접속이 제대로 안된다면 아래의 grafana 및 prometheus server 접근 불가 항목을 보면 된다.
처음 접속하는 계정은 admin/admin이다.
 Grafana 화면
Grafana 화면
추가 사항
1. grafana 및 prometheus server 접근 불가
kube-prometheus v0.11.0 버전부터 생긴 networkPolicy로 인하여 생기는 이슈로 확인(정확하지 않음)이 된다.
policyType을 따라 기본적으로 egress와 ingress에만 적용되기 때문에 Labels에 적용된 대상만 접근이 가능하다.
Cloud와 같이 public망을 사용하지 않는다면, on-premises(legacy) 환경에서 NAT처리로 인하여 사용 할 일이 없기 때문에NetworkPolicy를 지워줘도 된다.
https://github.com/prometheus-operator/kube-prometheus/issues/1763#issuecomment-1139553506
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# NetworkPolicy 확인
dor1@is-master:~$ kubectl get networkpolicies -n monitoring
NAME POD-SELECTOR AGE
alertmanager-main app.kubernetes.io/component=alert-router,app.kubernetes.io/instance=main,app.kubernetes.io/name=alertmanager,app.kubernetes.io/part-of=kube-prometheus 64s
blackbox-exporter app.kubernetes.io/component=exporter,app.kubernetes.io/name=blackbox-exporter,app.kubernetes.io/part-of=kube-prometheus 64s
grafana app.kubernetes.io/component=grafana,app.kubernetes.io/name=grafana,app.kubernetes.io/part-of=kube-prometheus 64s
kube-state-metrics app.kubernetes.io/component=exporter,app.kubernetes.io/name=kube-state-metrics,app.kubernetes.io/part-of=kube-prometheus 64s
node-exporter app.kubernetes.io/component=exporter,app.kubernetes.io/name=node-exporter,app.kubernetes.io/part-of=kube-prometheus 64s
prometheus-adapter app.kubernetes.io/component=metrics-adapter,app.kubernetes.io/name=prometheus-adapter,app.kubernetes.io/part-of=kube-prometheus 64s
prometheus-k8s app.kubernetes.io/component=prometheus,app.kubernetes.io/instance=k8s,app.kubernetes.io/name=prometheus,app.kubernetes.io/part-of=kube-prometheus 64s
prometheus-operator app.kubernetes.io/component=controller,app.kubernetes.io/name=prometheus-operator,app.kubernetes.io/part-of=kube-prometheus 64s
# NetworkPolicy 삭제
dor1@is-master:~$ kubectl delete networkpolicies -n monitoring --all
networkpolicy.networking.k8s.io "alertmanager-main" deleted
networkpolicy.networking.k8s.io "blackbox-exporter" deleted
networkpolicy.networking.k8s.io "grafana" deleted
networkpolicy.networking.k8s.io "kube-state-metrics" deleted
networkpolicy.networking.k8s.io "node-exporter" deleted
networkpolicy.networking.k8s.io "prometheus-adapter" deleted
networkpolicy.networking.k8s.io "prometheus-k8s" deleted
networkpolicy.networking.k8s.io "prometheus-operator" deleted
2. grafana의 dashboard가 provisioned로 인하여 수정 불가
grafana는 기본적으로 provisioned 되어 있는 항목은 수정이 불가능하도록 되어있다.
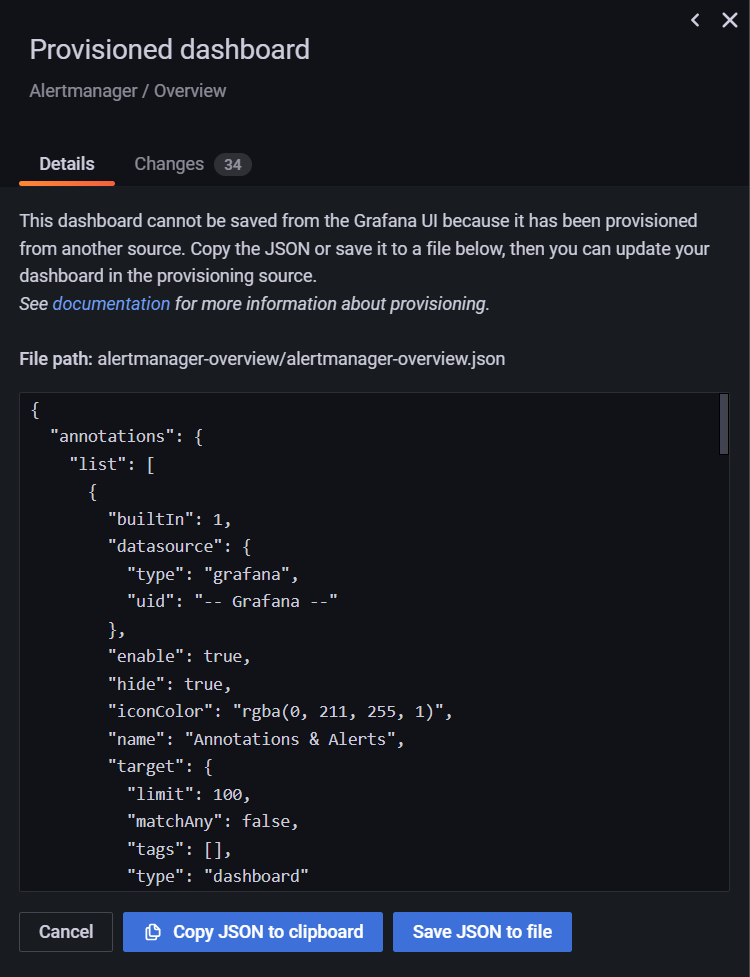 Provisioned dashboard로 인해 저장 및 수정 불가
Provisioned dashboard로 인해 저장 및 수정 불가
grafana의 설정을 확인해보면 allowUiUpdates 항목이 존재한다.
이 항목을 true로 추가해주면 수정이 가능해진다.
https://grafana.com/docs/grafana/latest/administration/provisioning/#dashboards
보통 config 또는 grafana의 dashboard json의 내용은 k8s에서 ConfigMap으로 저장되므로 해당 항목을 바꿔주면 된다.
변경 이후에 configMap은 적용되지만, pod에는 바로 적용 되지 않기 때문에 삭제키면 된다.
statefulSet으로 구성하게 된다면 pod를 삭제를 시켜도 자동으로 pod가 복구 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
dor1@is-master:~$ kubectl get cm -n monitoring
NAME DATA AGE
adapter-config 1 23m
blackbox-exporter-configuration 1 23m
grafana-dashboard-alertmanager-overview 1 23m
grafana-dashboard-apiserver 1 23m
grafana-dashboard-cluster-total 1 23m
grafana-dashboard-controller-manager 1 23m
grafana-dashboard-grafana-overview 1 23m
grafana-dashboard-k8s-resources-cluster 1 23m
grafana-dashboard-k8s-resources-namespace 1 23m
grafana-dashboard-k8s-resources-node 1 23m
grafana-dashboard-k8s-resources-pod 1 23m
grafana-dashboard-k8s-resources-workload 1 23m
grafana-dashboard-k8s-resources-workloads-namespace 1 23m
grafana-dashboard-kubelet 1 23m
grafana-dashboard-namespace-by-pod 1 23m
grafana-dashboard-namespace-by-workload 1 23m
grafana-dashboard-node-cluster-rsrc-use 1 23m
grafana-dashboard-node-rsrc-use 1 23m
grafana-dashboard-nodes 1 23m
grafana-dashboard-nodes-darwin 1 23m
grafana-dashboard-persistentvolumesusage 1 23m
grafana-dashboard-pod-total 1 23m
grafana-dashboard-prometheus 1 23m
grafana-dashboard-prometheus-remote-write 1 23m
grafana-dashboard-proxy 1 23m
grafana-dashboard-scheduler 1 23m
grafana-dashboard-workload-total 1 23m
grafana-dashboards 1 23m
kube-root-ca.crt 1 3h43m
prometheus-k8s-rulefiles-0 8 23m
# grafana config는 grafana-dashboard에 존재
dor1@is-master:~$ kubectl edit cm -n monitoring grafana-dashboards
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
data:
dashboards.yaml: |-
{
"apiVersion": 1,
"providers": [
{
"folder": "kube-prometheus",
"folderUid": "",
"name": "0",
"options": {
"path": "/grafana-dashboard-definitions/0"
},
"orgId": 1,
"type": "file",
# 추가 항목(json 형식으로 입력 시 상단에 ","을 빼먹지 말 것)
"allowUiUpdates": "true"
}
]
}
kind: ConfigMap
metadata:
creationTimestamp: "2023-02-10T05:57:51Z"
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 9.3.2
name: grafana-dashboards
namespace: monitoring
resourceVersion: "1577502"
uid: 69309e29-80a1-4e7c-ad11-75e92286f029
configmap/grafana-dashboards edited
# pod 확인
dor1@is-master:~$ kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 30m
alertmanager-main-1 2/2 Running 0 30m
alertmanager-main-2 2/2 Running 0 30m
blackbox-exporter-58c9c5ff8d-92nlc 3/3 Running 0 31m
grafana-59d96cb767-2jnr9 1/1 Running 0 31m
kube-state-metrics-6d454b6f84-8bf8r 3/3 Running 0 31m
node-exporter-6wd54 2/2 Running 0 31m
node-exporter-j6kmd 2/2 Running 0 31m
node-exporter-q67hx 2/2 Running 0 31m
node-exporter-qs7nf 2/2 Running 0 31m
prometheus-adapter-678b454b8b-h55gr 1/1 Running 1 (29m ago) 31m
prometheus-adapter-678b454b8b-lj446 1/1 Running 0 31m
prometheus-k8s-0 2/2 Running 0 30m
prometheus-k8s-1 2/2 Running 0 30m
prometheus-operator-7bb9877c54-vk8mt 2/2 Running 0 31m
# pod 삭제
dor1@is-master:~$ kubectl delete pod -n monitoring grafana-59d96cb767-2jnr9
pod "grafana-59d96cb767-2jnr9" deleted
# pod 확인
dor1@is-master:~$ kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 37m
alertmanager-main-1 2/2 Running 0 37m
alertmanager-main-2 2/2 Running 0 37m
blackbox-exporter-58c9c5ff8d-92nlc 3/3 Running 0 37m
grafana-59d96cb767-26788 1/1 Running 0 2m54s
kube-state-metrics-6d454b6f84-8bf8r 3/3 Running 0 37m
node-exporter-6wd54 2/2 Running 0 37m
node-exporter-j6kmd 2/2 Running 0 37m
node-exporter-q67hx 2/2 Running 0 37m
node-exporter-qs7nf 2/2 Running 0 37m
prometheus-adapter-678b454b8b-h55gr 1/1 Running 1 (36m ago) 37m
prometheus-adapter-678b454b8b-lj446 1/1 Running 0 37m
prometheus-k8s-0 2/2 Running 0 37m
prometheus-k8s-1 2/2 Running 0 37m
prometheus-operator-7bb9877c54-vk8mt 2/2 Running 0 37m
정상적으로 pod가 올라온 뒤 다시 확인해보면 적용이 잘 되어있다.
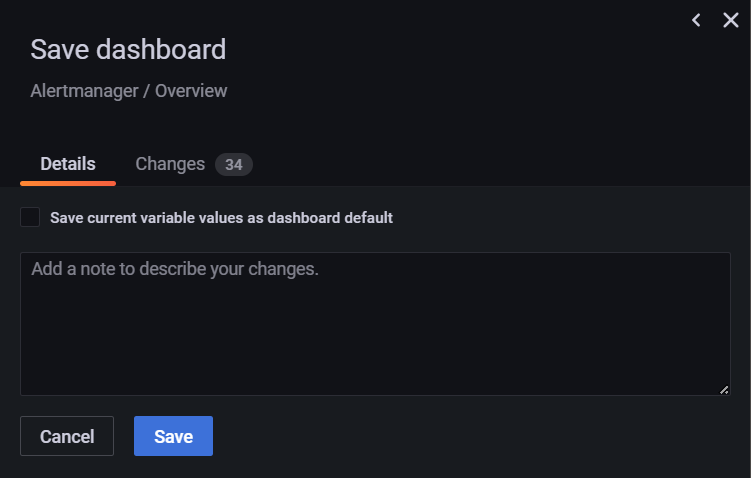 Provisioned dashboard에 대해 저장이 가능
Provisioned dashboard에 대해 저장이 가능
3. grafana의 default TZ(TimeZone) 변경
변경은 deployment 때 grafana-config.yaml 항목에서 쉽게 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
dor1@is-master:~$ vi grafana-config.yaml
apiVersion: v1
kind: Secret
metadata:
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 9.3.2
name: grafana-config
namespace: monitoring
stringData:
# UTC -> Asia/Seoul
grafana.ini: |
[date_formats]
default_timezone = Asia/Seoul
type: Opaque
provisioned dashboard들은 일일이 grafana-dashboardDefinitions.yaml 항목에서 수정을 해야 하며, json으로 되어있는 형식을 그대로 import 하는 방식이다 보니 grafana json의 항목 대로 timezone은 brower로도 설정이 가능하다.